
Converting Markdown to DOCX with Python: Automating Documentation from Markdown Linked Files
Converting Markdown to DOCX with Python: Automating Documentation from Markdown Linked Files
Overview
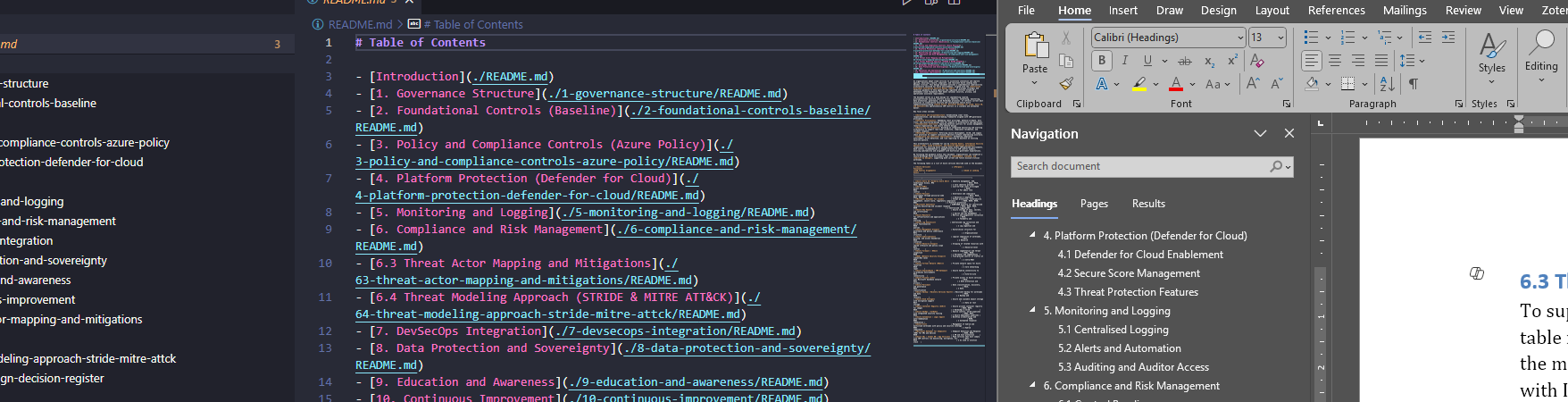
When working in structured cloud or cybersecurity documentation projects (such as defining an Azure Landing Zone), it’s common to maintain Markdown files for version control and team editing. However, stakeholders often expect polished Word documents.
This blog introduces a Python tool help to bridges this gap. It reads a README.md file, extracts links to additional Markdown documents, and compiles them into a basic professionally styled DOCX file, preserving headers, tables, lists, and block quotes. The inforamtion can then be updated with the required styles and adding images etc. The script helps with the process by combining the readme files into a word document.
Features
- Converts Markdown files to Microsoft Word
.docx - Supports headings (
#), paragraphs, bullet/numbered lists, blockquotes, and tables - Extracts links from a README file to include additional documentation
- Automatically inserts page breaks for each linked document
- Modular functions for easy maintenance and extension
Dependencies
Ensure the following Python packages are installed:
pip install markdown beautifulsoup4 python-docx
How It Works
- Extract Markdown links from a central
README.mdfile. - Convert each file from Markdown to HTML using the
markdownmodule. - Parse the HTML using
BeautifulSoup. - Translate HTML tags into Word elements using
python-docx. - Compile and save the final document.
Code
"""
Markdown to DOCX Converter with README Link Support
Version: 1.1
Author: Craig Wilson
Date: 2025-02-20
Description:
This script reads a Markdown README file, extracts links to other markdown documents,
converts each to HTML using the `markdown` module with table support,
then parses the HTML using BeautifulSoup to construct a Word document
using python-docx. The output is a consolidated DOCX representing all linked content.
Dependencies:
- markdown
- beautifulsoup4
- python-docx
Usage:
python md_to_docx.py <root_folder> <readme_path> <output_docx>
Example:
python md_to_docx.py ./docs ./docs/README.md ./output/architecture.docx
"""
import os
import sys
import re
import markdown
from bs4 import BeautifulSoup
from docx import Document
def markdown_to_html_soup(md_content):
"""
Convert Markdown text to a BeautifulSoup-parsable HTML structure.
Args:
md_content (str): The raw Markdown content.
Returns:
BeautifulSoup: Parsed HTML content as a soup object.
"""
html = markdown.markdown(md_content, extensions=['tables'])
return BeautifulSoup(html, "html.parser")
def add_html_to_docx(soup, doc):
"""
Add parsed HTML content to a Word document object.
Args:
soup (BeautifulSoup): Parsed HTML content.
doc (Document): The python-docx Document object to append to.
"""
for elem in soup.contents:
if elem.name and elem.name.startswith('h'):
level = int(elem.name[1])
doc.add_heading(elem.get_text(), level=level)
elif elem.name == 'p':
doc.add_paragraph(elem.get_text())
elif elem.name in ['ul', 'ol']:
style = 'List Bullet' if elem.name == 'ul' else 'List Number'
for li in elem.find_all('li'):
doc.add_paragraph(li.get_text(), style=style)
elif elem.name == 'blockquote':
doc.add_paragraph(elem.get_text(), style='Intense Quote')
elif elem.name == 'table':
rows = elem.find_all('tr')
if rows:
cols = rows[0].find_all(['td', 'th'])
table = doc.add_table(rows=len(rows), cols=len(cols))
for i, row in enumerate(rows):
for j, cell in enumerate(row.find_all(['td', 'th'])):
table.cell(i, j).text = cell.get_text()
def extract_links_from_readme(readme_path):
"""
Extract Markdown-style links from a README file.
Args:
readme_path (str): Path to the README file.
Returns:
list[str]: List of linked file paths.
"""
with open(readme_path, 'r', encoding='utf-8') as f:
content = f.read()
return re.findall(r'\[.*?\]\((.*?)\)', content)
def create_word_document(root_folder, readme_path, output_path):
"""
Create a Word document by reading Markdown files referenced in the README.
Args:
root_folder (str): Base folder to resolve relative Markdown paths.
readme_path (str): Path to the README markdown file.
output_path (str): Destination path for the output DOCX file.
"""
doc = Document()
doc.add_heading("Azure Landing Zone Cybersecurity Architecture", 0)
links = extract_links_from_readme(readme_path)
for link in links:
full_path = os.path.join(root_folder, link)
if os.path.exists(full_path):
with open(full_path, 'r', encoding='utf-8') as f:
md = f.read()
soup = markdown_to_html_soup(md)
doc.add_page_break()
add_html_to_docx(soup, doc)
else:
print(f"WARNING: File not found - {full_path}")
doc.save(output_path)
print(f"✅ Document saved to: {output_path}")
if __name__ == "__main__":
if len(sys.argv) != 4:
print("Usage: python md_to_docx.py <root_folder> <readme_path> <output_docx>")
sys.exit(1)
root_folder = sys.argv[1]
readme_path = sys.argv[2]
output_path = sys.argv[3]
create_word_document(root_folder, readme_path, output_path)
Usage
python md_to_docx.py <root_folder> <readme_path> <output_docx>
Example:
python md_to_docx.py ./docs ./docs/README.md ./output/architecture.docx
Use Cases
- Cloud architecture documentation (e.g., Azure Landing Zone)
- DevOps or security engineering workflows
- Academic thesis chapters written in Markdown
- Policy documentation generated from version-controlled repositories
Repository Structure Suggestion
/docs
├─ README.md ← Includes links to .md content
├─ 01-intro.md
├─ 02-architecture.md
└─ 03-controls.md
With links in README.md like:
[Introduction](01-intro.md)
[Architecture](02-architecture.md)
[Controls](03-controls.md)
Roadmap or addtional TODO tasks
- Support for embedded images
- Styling customization (fonts, margins)
- HTML-to-DOCX stylesheet mapping
Final Thoughts
This tool offers a clean and automated way to transform version-controlled Markdown into stakeholder-ready documentation. It’s particularly useful for cybersecurity architects, cloud engineers, or anyone needing to convert technical documentation into formal deliverables.